
Is AI the new breadwinner?
When it comes to work and artificial intelligence, human replacement might not be baked in


This is a special multi-part edition of Post Haste, exploring AI’s effect on the labour market. Make sure you’re subscribed to read all three instalments.

By Dr Pedro Serôdio (@pdmsero)
We often talk about AI as though it is on an inevitable path to job destruction. But what AI can do at the frontier, and how human-like it becomes, may be less economically relevant than the order in which it progresses – what it masters first, what it struggles to grok, or perhaps what it never acquires.
Last month I wrote about how AI is, so far, not taking your job. But this month I wanted to step back and answer a broader question: what would it actually mean for AI to be coming for your job? The signal in the data is still weak, and a small signal on its own cannot tell you whether you are looking at the calm before the storm or whether the storm is not coming at all. To distinguish those, you need a framework: what AI substitution would look like, what its absence would look like, and which pattern fits the data. That turned out to go beyond the scope of a single post.
So, this piece is the first part of a short series, and looks at how there remain parts of human labour that resist codification, and at why the shape of AI capabilities – i.e. which tasks it masters first – matters as much as the frontier.
The second instalment will turn to the resulting economics: when does cheaper AI displace human labour, when does human labour still add value to the production process, and what does a complete theory of AI’s labour market effects need to say about firms as well as workers? The final post will be empirical evidence: what three years of UK data suggests about which scenario we are in.
Tacit knowledge and uneven AI progress
As lockdowns began across many countries during the Covid-19 pandemic, millions of people took up an unexpected interest in sourdough bread.
Sourdough was seemingly everywhere: in video tutorials, blog posts, step-by-step recipes timed to the minute and with precise measurements. The chemistry of sourdough is as simple as it gets: flour, water, salt, and yeast from the air around you. Add patience, and you get bread.

Even though sourdough is simple, most people struggled. The dough was too wet, or too dry, or rose at the wrong speed, or not at all. There was nothing wrong with the recipes. The problem was that bread-making is very sensitive to small local conditions: the humidity in your kitchen, the temperature of your water, the microbial ecosystem your particular starter developed over weeks. None of this can be found in any recipe because it doesn’t make sense for it to be: it is possible to specify more and more precise requirements at increasingly high costs, but doing so also raises the cost of following the recipe.
Those who eventually succeeded did so by developing a feel for the dough, a sense of how sticky is right, how stretchy is enough, when to wait and when to fold. They built mental heuristics through repeated failure that they would struggle to explain if you asked.
I want to draw a distinction here. Some knowledge hasn’t been written down yet because the cost isn’t worth it. Other knowledge cannot be written down because of what it is. The first kind is just a cost problem: someone could codify it, but the effort isn’t usually worth it for how rarely it’s needed. But the second kind is structural. It depends on sensory discrimination, pattern recognition, or contextual judgement that resists decomposition into rules.
Sourdough sits partly in that second category. You could teach someone in person, guide their hands through the dough and say “like this, not like that.” But writing it down in a way that transfers reliably is a different problem entirely.
Tacit work across the economy
This is not a curiosity confined to artisanal baking. A large share of economically valuable activity depends on exactly this second kind of knowledge, the kind that cannot simply be written down.
Whisky blending requires a master blender to integrate taste, smell, and dozens of other sensory inputs across 50 or more cask samples to maintain a house style that consumers expect to be consistent across decades. Gas chromatography can characterise the chemical composition of each cask, but chemical profiles do not map linearly onto perceived flavour. The blender’s judgement is the instrument.
Champagne production works in a similar way: Krug’s chef de cave evaluates over 250 base wines each year, and no analytical method has replicated the selection.
Chartreuse is an interesting case along another dimension - the power of secrecy. The liqueur is made by Carthusian monks using 130 plants, herbs, and flowers in a recipe dating from 1764. Only two monks know the full formula at any time, and they are never permitted to travel together.
When the French government expelled the order in 1903 and seized the distillery, a commercial firm attempted to replicate the product using chemical analysis. It was a commercial failure; consumers rejected it immediately. The monks continued producing the original in exile in Spain and eventually reclaimed the brand. Despite more than a century of modern analytical chemistry, no competitor has produced an imitation widely regarded as equivalent to the original. In 2023, the monks announced they would limit production to protect their monastic life. No competitor has filled the gap, because there is no gap to fill without the knowledge those two monks carry.

This pattern holds even at higher levels of capital intensity and technological sophistication. Semiconductor fabrication plants are among the most expensive facilities ever built, yet yield improvement depends on tacit knowledge held by process engineers.
When TSMC or Intel transfer a process to a new fab with identical equipment and identical written procedures, the new facility can often experience large yield gaps during ramp-up - sometimes by tens of percentage points. The gap, worth billions in lost revenue, comes down to diagnostic intuitions that experienced engineers have accumulated through years of pattern recognition: the particular spatial distribution of defects across a wafer that signals a contamination source, the subtle drift in etch uniformity that precedes a larger failure. This knowledge is distributed across teams and embedded in organisational routines. It cannot be hired away by a competitor because no single person holds it.
Medicine follows the same logic. An experienced cardiologist hearing a heart murmur can distinguish aortic stenosis from mitral regurgitation in seconds. The relevant acoustic features may resist explicit rule-based decomposition, even if statistical systems can sometimes infer them from data. Attempts to build expert diagnostic systems, from MYCIN in the 1970s to IBM Watson for Oncology in the 2010s, failed to match the performance of experienced clinicians in many complex real-world settings, not because the systems lacked medical knowledge, but because clinical diagnosis integrates perceptual cues, contextual judgement, and forms of tacit inference that can be difficult to capture reliably in training data or generalise across real-world settings.
Why tacit knowledge persists
David Autor framed this as the Polanyi paradox: the tasks humans perform tacitly are precisely the ones hardest to automate, because the programmers cannot specify what they cannot observe. Using evidence from the Horndal iron works, Kenneth Arrow also found that learning-by-doing accounted for productivity growth of roughly 2% per year.
The economists Nelson and Winter developed an evolutionary theory of firms centred on organisational routines: persistent, partly tacit patterns of behaviour that help explain why firm capabilities are sticky, hard to replicate, and do not flow freely between companies even in the same industry.
This kind of tacit knowledge is not a rounding error. British economists Jonathan Haskel and Stian Westlake estimate that intangible investment (which includes organisational capital, firm-specific human capital, and relational assets, much of it tacit) now exceeds tangible investment in both the UK and US.
Cowan, David, and Foray1 make a further point that codification and tacit knowledge are not substitutes; they are complements. The more knowledge an economy codifies into databases, standards, and protocols, the higher the returns to the tacit skills needed to interpret and apply that information. A richer medical literature does not reduce the need for clinical judgement. If anything, the explosion of codified information raises the premium on the human ability to synthesise it in context.
This does not mean that automation is impossible, or that it won’t replace human labour in certain tasks.
What strikes me, looking across these cases – semiconductor fabs, hospital wards, monastery cellars – is that the gap between performing a task in controlled conditions and performing it reliably in the world may be wider, and more persistent, than capability benchmarks imply.
Could AI replace all labour?
AI companies often assume that the technology will replace a large share of human work. OpenAI’s stated goal is to build systems that “outperform humans at most economically valuable work.” Anthropic’s CEO has predicted that AI could eliminate half of entry-level white-collar jobs within five years. The implicit model underlying investment into the industry is that AI capabilities will eventually generalise across most economically valuable cognitive labour, including many forms of tacit judgement and contextual reasoning currently performed by humans2.

If they are right, the consequences for workers, wages, and the structure of the economy are enormous. If they are wrong, the capital being deployed must generate large productivity gains to justify these levels of investment.
How AI capabilities might expand
There are two important dimensions: how the capabilities frontier advances, and how these capabilities are shaped – i.e. which capabilities are mastered when. Conventional assumptions on the former are that AI progress will inevitably result in a well-behaved capability set wherein the technology will be able to perform any task at some given cost. This view often hides additional assumptions about how thick and balanced the space of successful tasks will be. We can characterise some of these assumptions by plotting different paths for the expansion of AI capabilities.
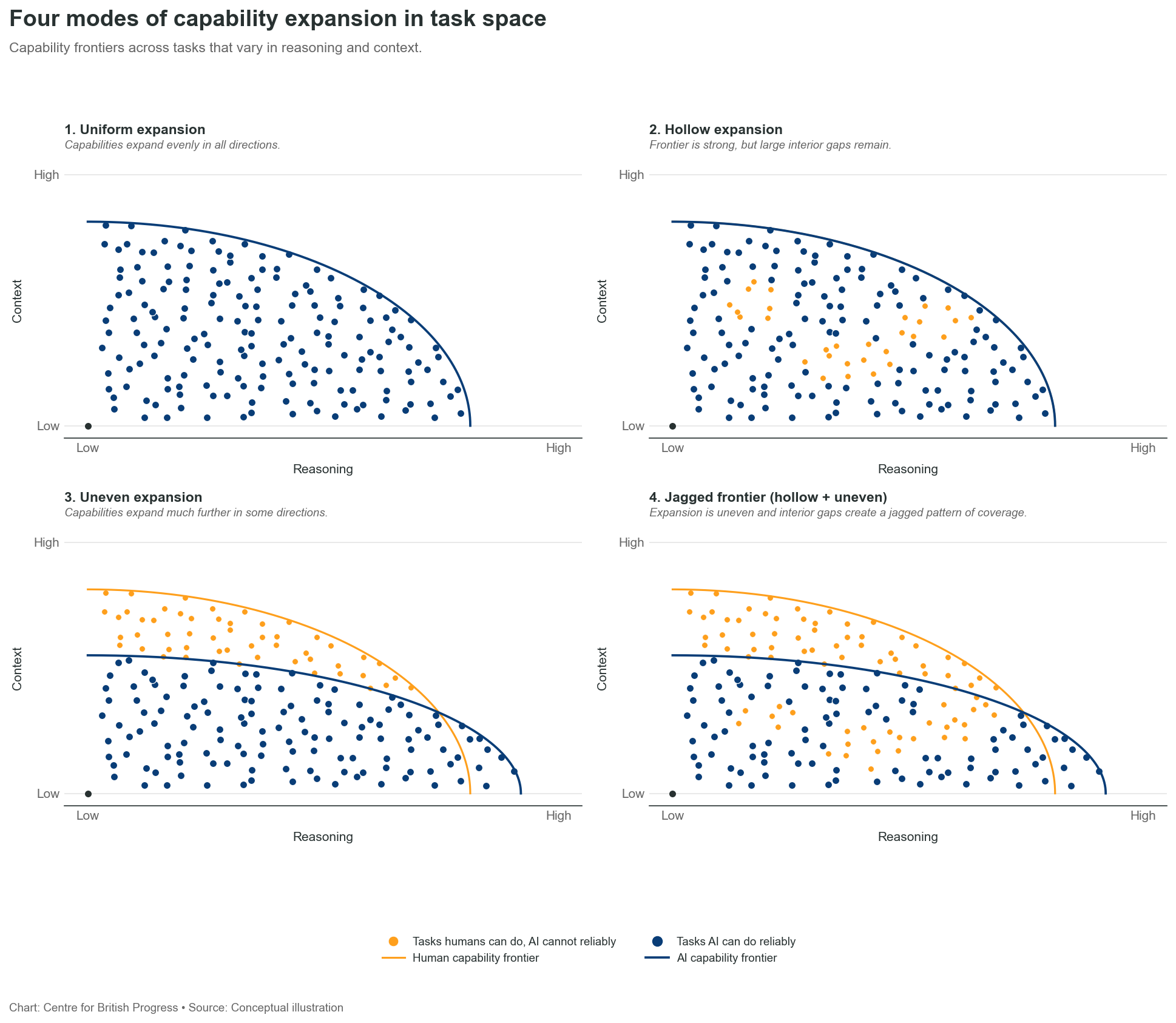
Scenario 1 (upper left) represents a common view of the evolution of AI capabilities: a smooth expansion along every dimension where all tasks currently performed by human workers are gradually replaced by a more efficient, automated version. In this view, the threshold of peak human capability is eventually crossed and any and all tasks can be automated.
But there are other possibilities. On at least two other dimensions, progress of AI capabilities might fall short of human ones: sparseness and specialisation. If AI advances the frontier of what tasks can be performed but leaves cognitive gaps that are easily performed by human labour, many human tasks will remain, the AI frontier advancing. This would result in a need to combine human and automated cognitive labour to produce useful output - generative AI wouldn’t fill those gaps on its own.
A similar consequence would follow if the natural progression of AI capabilities was tilted in a particular direction. For example, AIs may be rapidly achieve superhuman capabilities along many coding tasks, but fail to deliver simple tasks that are highly dependent on tacit knowledge and relationships (for instance, determining that it is not an appropriate time to communicate some bad news to a line manager because they’re dealing with another problem and may not have the bandwidth).
If AIs possess this natural tilt, their capabilities may more naturally expand in specific directions, and require considerable more effort and cost to rebalance.
It is important to note that these two dimensions are still highly compatible with a rapidly expanding frontier. While benchmarks can be very comprehensive, they cannot fully capture the entire task space, and are by their nature focused on the capabilities that require more cognitive ability. As a result, they are not well-placed to evaluate how well AIs perform many less complex tasks that human workers routinely carry out.
The decision to expand the frontier in a particular direction may require effort. Generality across all dimensions relevant for human cognitive labour may not happen automatically - it hasn’t so far, and in any case the current architecture of AI models is an awkward fit for the totality of the human sensory and cognitive nexus.
Benchmarks vs economic deployment
The production of semiconductors remains a useful litmus test. When companies encounter those yield gaps when ramping up a new fab, the shortfall measures what cannot be written down. The engineers do not lack the concepts. What they have to rebuild is a complex web of tacit knowledge that binds together the technical specifications that can be written down: the pattern recognition a team accumulates across hundreds of failure modes.
Capability benchmarks measure performance under somewhat contrived evaluations. But economic deployment is a higher bar, because real work also runs on tacit knowledge.
Coming soon… The next instalment turns to the economics of automation: under what conditions does cheaper AI displace human labour, and when does it not?
The Explicit Economics of Knowledge Codification and Tacitness is a very useful introduction to the concept of tacit knowledge in how it relates to economic activity.
There is a widespread assumption that if this does not hold, these investments will not pay off. That conclusion is unwarranted: what matters for returns is whether model developers and providers induce and capture enough economic value from higher productivity. The question of whether human labour is replaced is orthogonal to this.
 | A guest post by
|